LLM World Models
10-07TL;DR: How much world knowledge do LLMs have? To see, I ask them what's Texas and what's not.
Methodology
We use the EPSF:3083 projection, an equal-area projection centered on Texas. We split the map into an N×N grid (64 or 128, depending on budget) and convert each point on the grid to latitude X and longitude Y.
The prompt:
> Output exactly one of: Texas, Not Texas. If the coordinate is inside the land borders of the U.S. state of Texas, answer 'Texas'. Otherwise answer 'Not Texas'. Do not say anything else. Latitude: X°, Longitude: Y°.
For models that support logprobs, we can calculate p(texas). For models that don't, we sample the model multiple times.
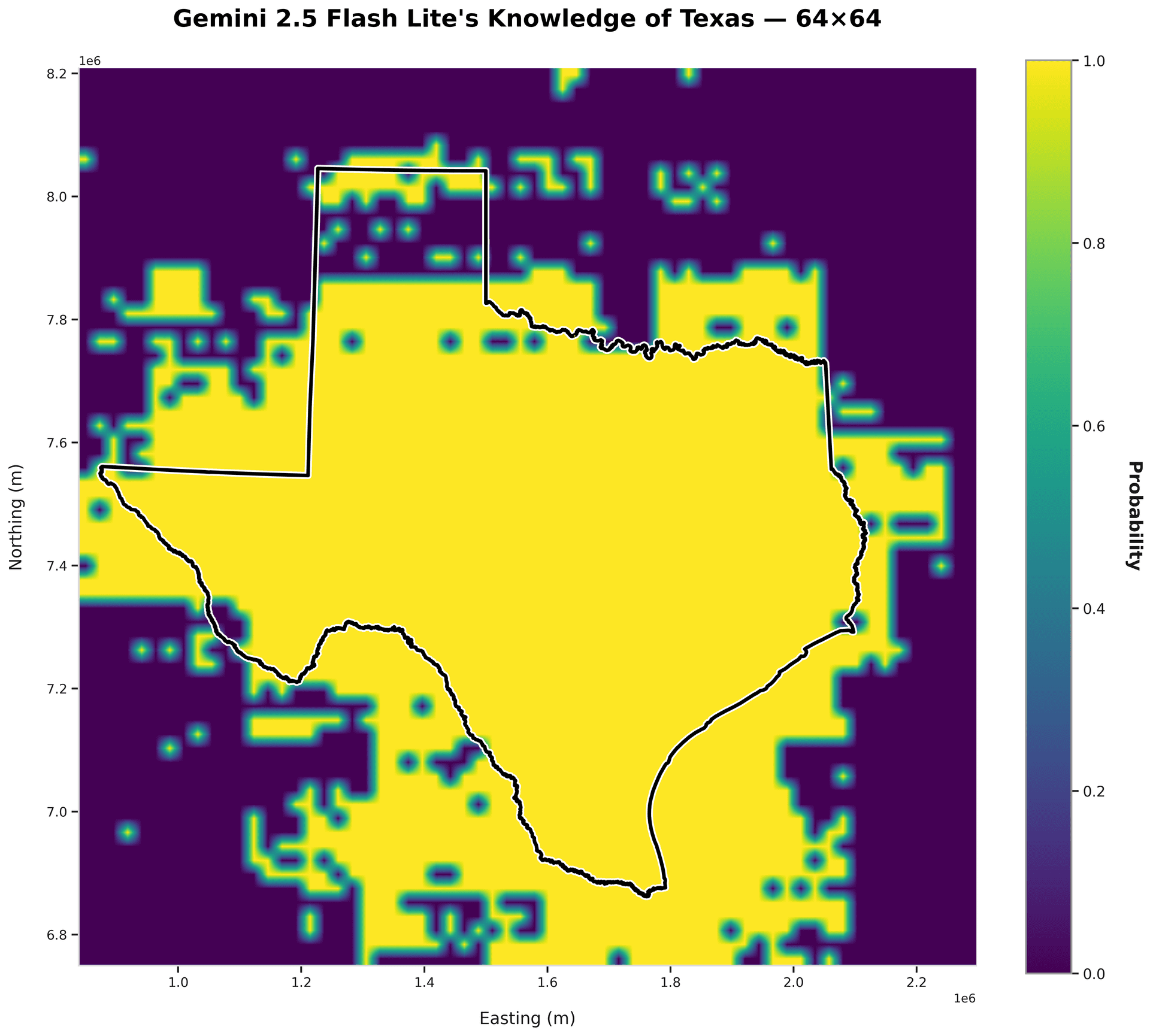
gemini-2.5-flash-lite
accuracy: 74.8%
precision: 55.8%
Overly optimistic!
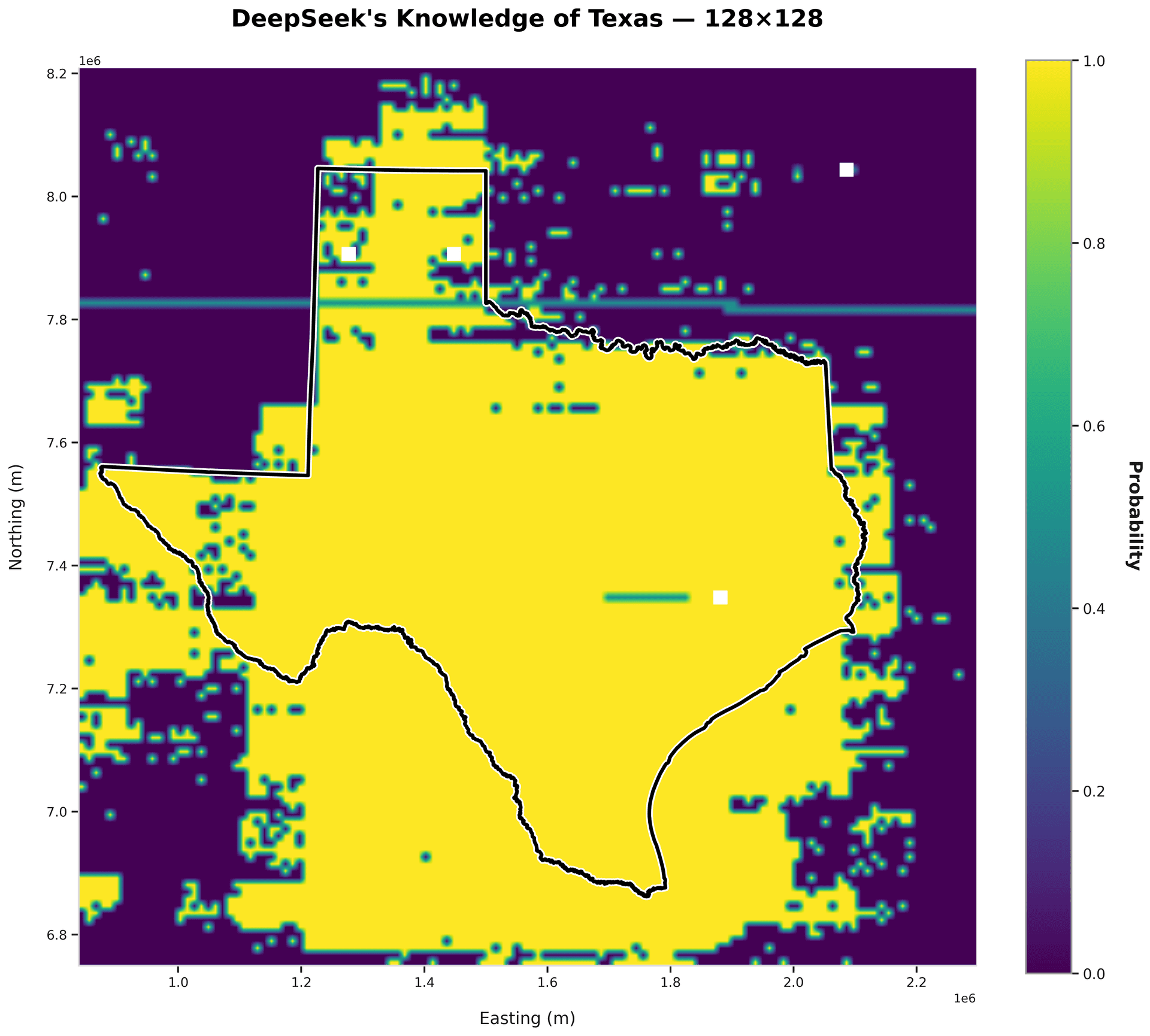
deepseek-v3.2
accuracy: 74.7%
precision: 56.3%
Good performance - notice the adherence to the two straight sides on the left.
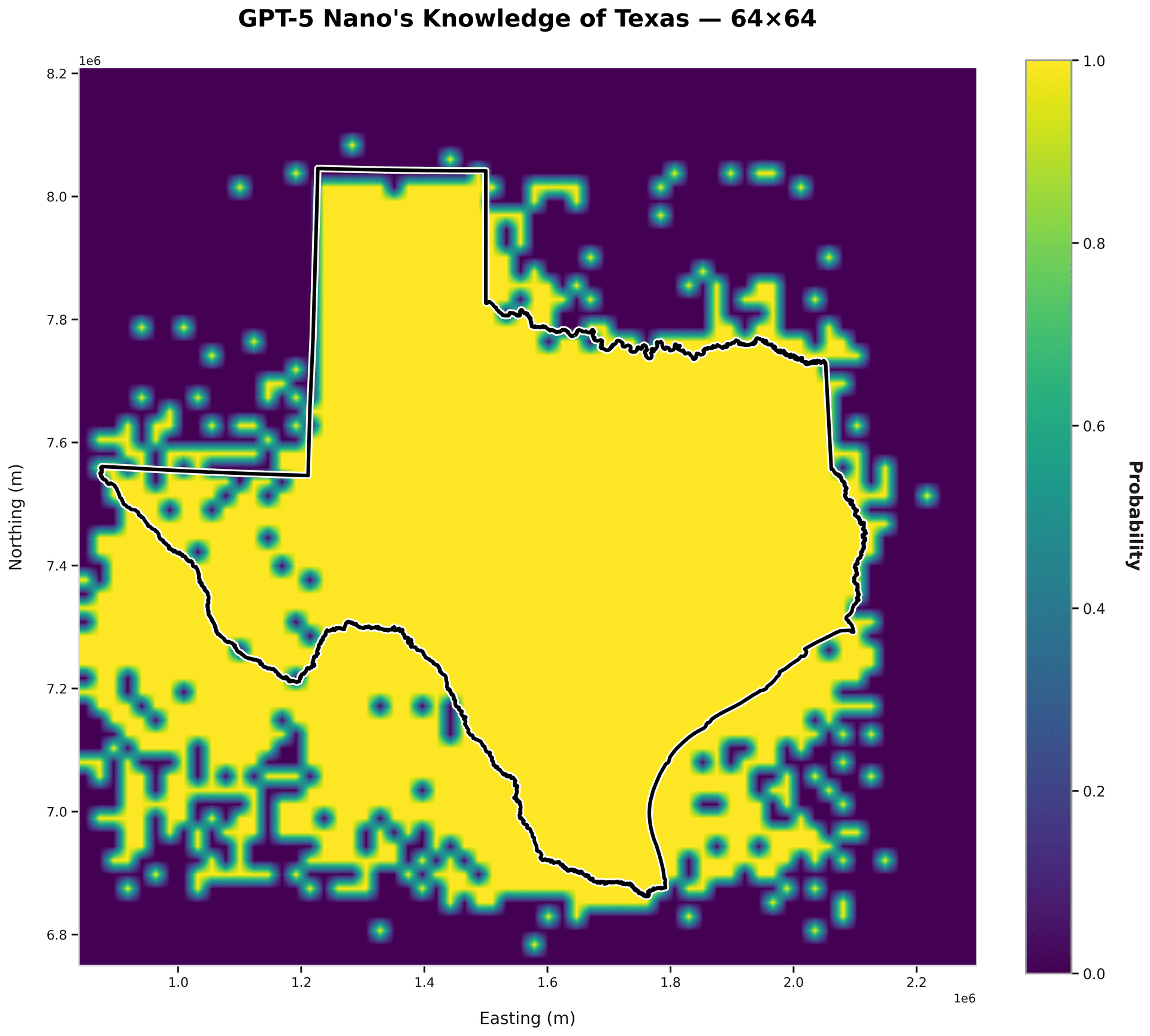
gpt-5-nano
accuracy: 79.6%
precision: 61.3%
Almost perfect adherence on the top half - bottom half is shaky.
Conclusion
No model successfully describes the bottom half of Texas (yet). The models appear to know of state borders, but struggle with the irregular geometry of coastlines. It is possible that geometric simplicity and frequent textual reference drive stronger spatial representations. One way to truly gauge the quality of an LLM's world model, then, is a benchmark on coastline accuracy. Maybe these natural borders are more difficult to encode than political ones.